Course Overview
An intensive exploration of advanced computer architecture and hardware-software co-design. The coursework focused on processor microarchitecture, memory hierarchy, cache coherence protocols (such as MSI), and hardware-level performance optimization. Assignments were heavily implemented in C and RISC-V Assembly to analyze instruction-level parallelism, pipeline behavior, and data-level parallelism via vector extensions.
Core Laboratory Projects
1. Microarchitectural Profiling & Pipeline Hazards
Co-designed and executed microbenchmarks in C to reverse-engineer hardware memory hierarchies and expose processor pipeline characteristics.
- Control Hazards & CPI Analysis: Developed highly-branched C code utilizing deeply nested ternary and
ifstatements to evaluate the processor’s branch penalty and maximize branch instructions. Demonstrated that when added branches are consistently not taken, control hazard penalties are bypassed. However, the program CPI still increased (reaching 1.494) primarily due to load-use hazards and pipeline stalls caused by a high frequency of memory load instructions. - Cache Hierarchy Reverse-Engineering: Engineered targeted memory striding accesses and measured latency using hardware performance counters (
rdcycle()) to map the cache topology. Successfully deduced the underlying hardware parameters through data analysis, confirming an L1 Data cache capacity of 16kB, a 64-byte line size, and an 8-way set associativity.
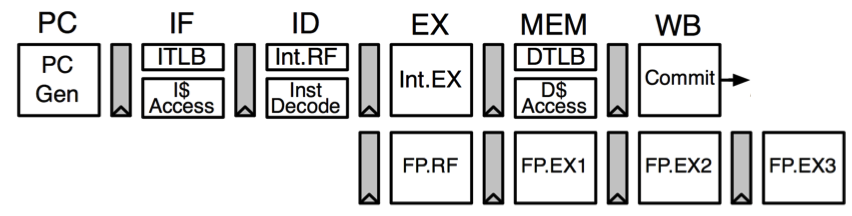
We worked on this specific Rocket Chip pipeline:
2. Alpha 21264 Tournament Branch Predictor
Co-architected a custom two-level tournament branch predictor in C to optimize instruction fetch efficiency for superscalar, out-of-order cores.
- Predictor Architecture: Implemented a hybrid predictor modeled after the Alpha 21264, featuring a 4096-entry global history table of 2-bit saturating counters. Integrated a 1024-entry local predictor indexed by PC, which feeds into a set of 3-bit counters. Designed a 4096-entry arbiter to dynamically select the most accurate prediction between the global and local outcomes.
- State Machine Optimization: Configured the state machine to default to “not-taken” initialization for optimal performance. Engineered the logic to update the arbiter counter one bit toward the correct predictor only when the global and local predictions diverged.
- Performance Evaluation: Analyzed IPC and prediction accuracy across multiple benchmarks, determining that short, repetitive branch behaviors yielded the highest accuracy because local histories were effectively utilized. Conversely, accuracy degraded on code requiring extensive global history. Explored index “folding” to support multiple global history lengths while avoiding exorbitant table sizes and hardware costs.
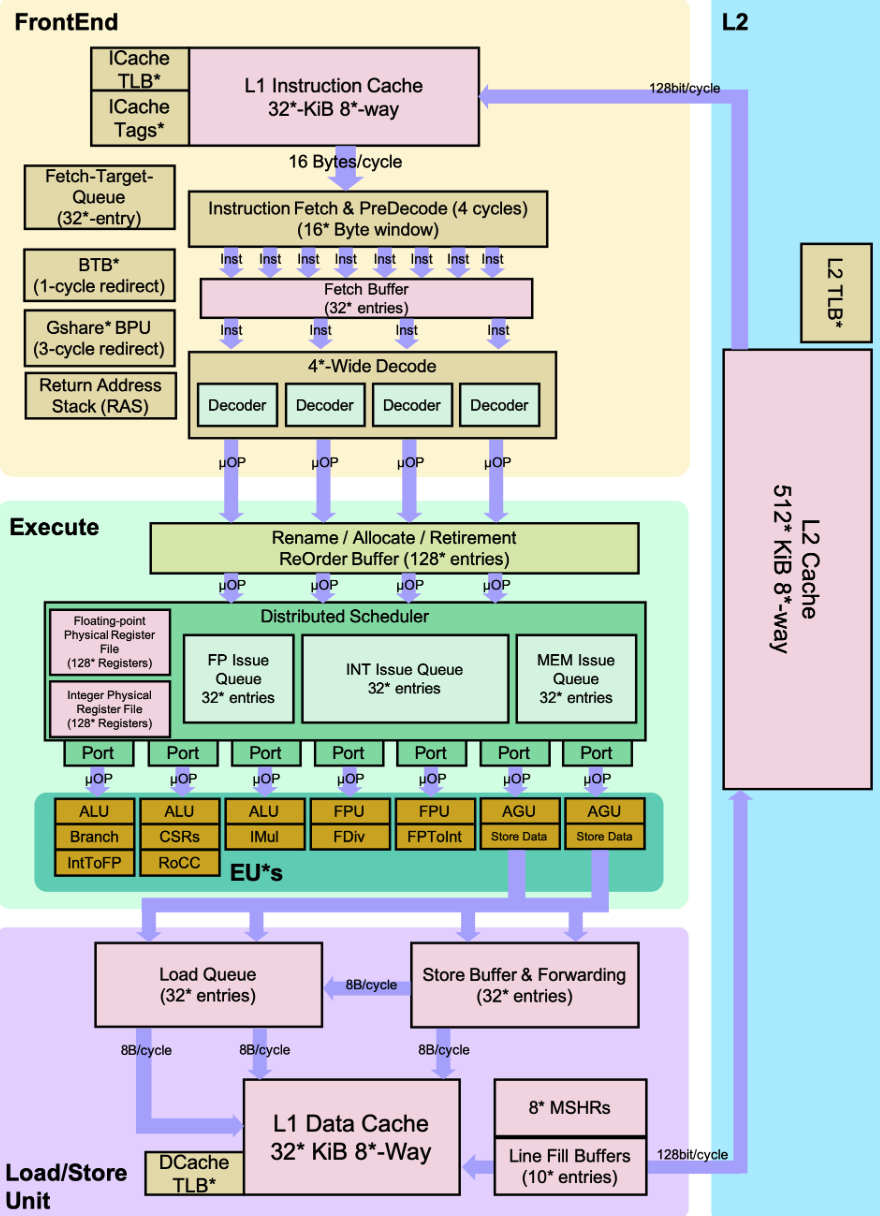
We worked on this specific Berkeley Out-of-Order Machine (BOOM) pipeline:
3. Data-Level Parallelism via RISC-V Vector Extensions
Co-implemented high-performance mathematical routines directly in RISC-V Vector Assembly to accelerate computationally bound vector and matrix operations.
- Vectorized Complex Arithmetic: Developed a vectorized complex multiplication routine (
cmplxmult). Utilized the RISC-Vvsetvliinstruction to dynamically configure the vector length (e32, m4) and leveraged vectorized fused multiply-accumulate and subtract instructions (vfmul.vv,vfnmsac.vv,vfmacc.vv) to process real and imaginary components concurrently. - Vectorized DGEMV: Engineered a double-precision matrix-vector multiplication kernel (
dgemv). Configured the vector configuration to 64-bit elements (e64, m8) and utilizedvfmacc.vvfor the core loop accumulations. Performed final vector reductions into a scalar floating-point register utilizingvfredsum.vsto compute the dot product outputs efficiently.
4. Multithreaded Matrix Multiplication & Cache Coherence
Co-engineered highly optimized multithreaded dense linear algebra kernels, demonstrating robust performance acceleration across varying hardware cache coherence protocols.
- Cross-Protocol Acceleration: Evaluated the
matmuloptimization against a naive baseline under both MI (Modified, Invalid) and MSI (Modified, Shared, Invalid) snooping protocols. The software-level optimizations yielded a ~7.0x speedup under the MI protocol (reducing cycles from 939,662 to 133,074) and a ~2.2x speedup under the MSI protocol (283,843 to 128,262), successfully converging the CPI to 1.7 in both environments. - Memory Access Optimization: Restructured matrix operations by pre-transposing input matrices to ensure continuous spatial locality. This algorithmic transformation effectively bridged the inherent hardware-level performance gap between MI and MSI by drastically minimizing cache invalidation overhead and false sharing on the memory bus.
- Concurrency Control: Utilized explicit synchronization and thread-local pointers (
*pb0++) to alleviate register pressure and maximize hardware resource utilization across parallel cores without triggering unnecessary coherence traffic.
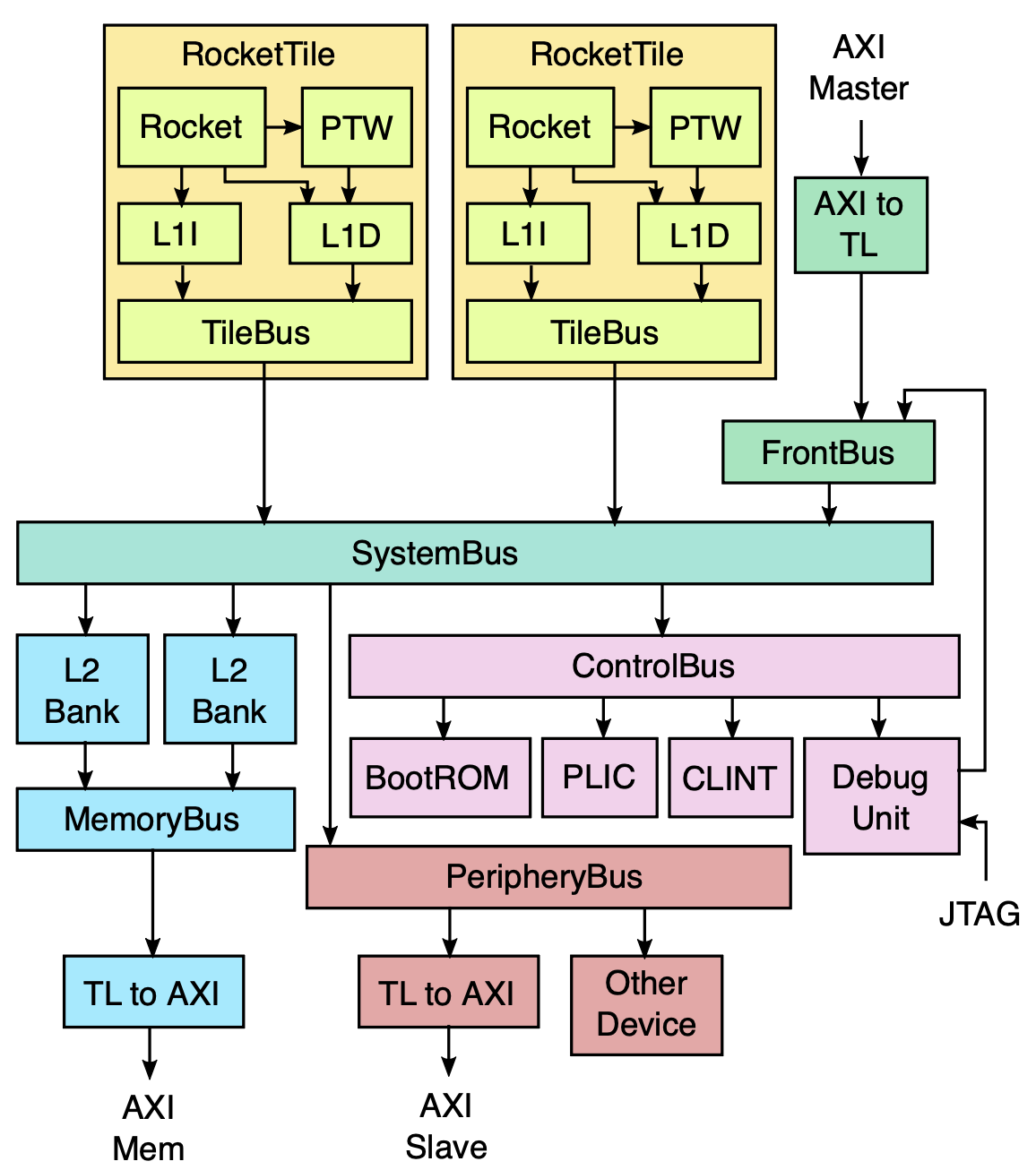
We worked on this specific Rocket Chip instance:
Technical Stack
- Languages: C, RISC-V Assembly, Chisel
- Concepts: Out-of-Order Execution, Microcoded Control, Branch Prediction, Memory Hierarchy, Cache Coherence Protocols, Vector-Matrix Multiplication.
- Tools: Chipyard.